

一般的站长是不会管蜘蛛的,比如󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮百度,搜狗,bing,Google等蜘蛛会给你带来搜󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮索排名和流量,这些好蜘蛛我们是不会管的。
40.77.167.115 - - [07/Jul/2023:19:40:38 +0800] "GET / HTTP/2.0" 200 17219 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/103.0.5060.134 Safari/537.36"但有时候,垃圾蜘蛛也同样访问你的网站,如果有大量垃圾蜘蛛访问(甚至网站被爬虫访问)则很影响性能,导致CPU占用过高!
54.36.149.47 - - [07/Jul/2023:19:43:16 +0800] "GET /author/2?tab=post&orderby=favorite_count&status=publish HTTP/2.0" 200 12487 "-" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)"那么我们该怎样屏蔽掉垃圾蜘蛛呢?一般来说,屏蔽蜘蛛的爬取有三种方法:
- Robots 禁封
- UA 禁封
- IP 禁封
一、Robots 禁封
Robots 协议(也称为爬虫协议、机器人协议等),用来告诉搜索引擎、爬虫哪些页面可以抓取,哪些页面不能抓取。
R󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮obots 协议在网站中体现在根目录下的󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮 robot󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮s.txt 文件,一般格式入下:
# JuanYi Blog Robots - https://jy.cyou/
Sitemap: https://jy.cyou/sitemap.xml
Sitemap: https://jy.cyou/sitemap-news.xml
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
User-agent:AhrefsBot
User-agent: dotbot
Disallow: /每条记录均由 字段: 值 组成,如 :
Sitemap:󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮 https://example.com/sitemap.xml
User-agent:用于指定指令所作用于的目标抓取工具(网络蜘蛛),后接抓取工具名称;Disallow:指定不允许抓取的目录或网页,后面为空则表示允许抓取一切页面;Allow:指定允许抓取的目录或网页;Sitemap:站点地图的位置,必须是绝对路径;*:表示通配符;$:表示网址结束;/:匹配根目录以及任何下级网址。
正规 Robot 在爬取网站前都会先读取该文件,根据 robots.txt 指示爬取:
这里我分享一个屏蔽大多数国外爬虫的robots.txt
User-agent: MJ12bot
User-agent: YisouSpider
User-agent: SemrushBot
User-agent: SemrushBot-SA
User-agent: SemrushBot-BA
User-agent: SemrushBot-SI
User-agent: SemrushBot-SWA
User-agent: SemrushBot-CT
User-agent: SemrushBot-BM
User-agent: SemrushBot-SEOAB
user-agent: AhrefsBot
User-agent: DotBot
User-agent: MegaIndex.ru
User-agent: ZoominfoBot
User-agent: Mail.Ru
User-agent: BLEXBot
User-agent: ExtLinksBot
User-agent: aiHitBot
User-agent: Researchscan
User-agent: DnyzBot
User-agent: spbot
User-agent: YandexBot
Disallow: /二、UA 禁封
UA(User Agent)中文名为用户代理,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,大多数蜘蛛都有携带此信息,如谷歌 Chrome 浏览器 Windows 版本 UA 是:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36针对指定 UA 的访问,返回预先设定好的异常页面(如 403,500)或跳转到其他页面的情况,即为 UA 禁封。
Ngi󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮nx 下,可以单独创建一个配置文件,如 deny-robots.󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮conf,并将文件添加到网站配置中,然后重新加󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮载 Nginx 即可。
例如在 /󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮www/server/nginx/conf 文件夹下创建deny-robots.conf,其内容为:
if ($http_user_agent ~ "InetURL|Pcore-HTTP|PocketParser|Wotbox|SEMrushBot|newspaper|DnyzBot|Mechanize|redback|ips-agent|Sogou Pic Spider|python-requests|PiplBot|SMTBot|WinHTTP|Auto Spider 1.0|GrabNet|TurnitinBot|Go-Ahead-Got-It|Download Demon|Go!Zilla|GetWeb!|GetRight|libwww-perl|Cliqzbot|MailChimp|SMTBot|Dataprovider|XoviBot|linkdexbot|feedreader|SeznamBot|Qwantify|spbot|evc-batch|zgrab|Go-http-client|FeedDemon|JikeSpider|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|YisouSpider|HttpClient|MJ12bot|heritrix|EasouSpider|LinkpadBot|Ezooms|^$")
{
return 444;
}在网站配置中添加:
server {
......
#屏蔽Robots
include deny-robots.conf
......
}然后,重启nginx即可生效,Apache 等其他软件操作类似。
service nginx reload解释一下,这个配置的意思是 判断访问者 UA 是否包含引号中的字符串,若为真,则返回错误码 444,其中错误码 444 是 nginx 独有的错误码,表示服务器不返回任何数据,直接丢弃。
由于 UA 禁封是由 Nginx 或󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮 Apache 等已经到应用层才处󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄠󠄬󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮理,因此即使已经禁止爬取访问,蜘蛛仍然会先与服务器创建连接,浪费资源,为此,针对特别流氓的蜘蛛,可以通过防火墙在底层拒绝连接。
三、IP 禁封
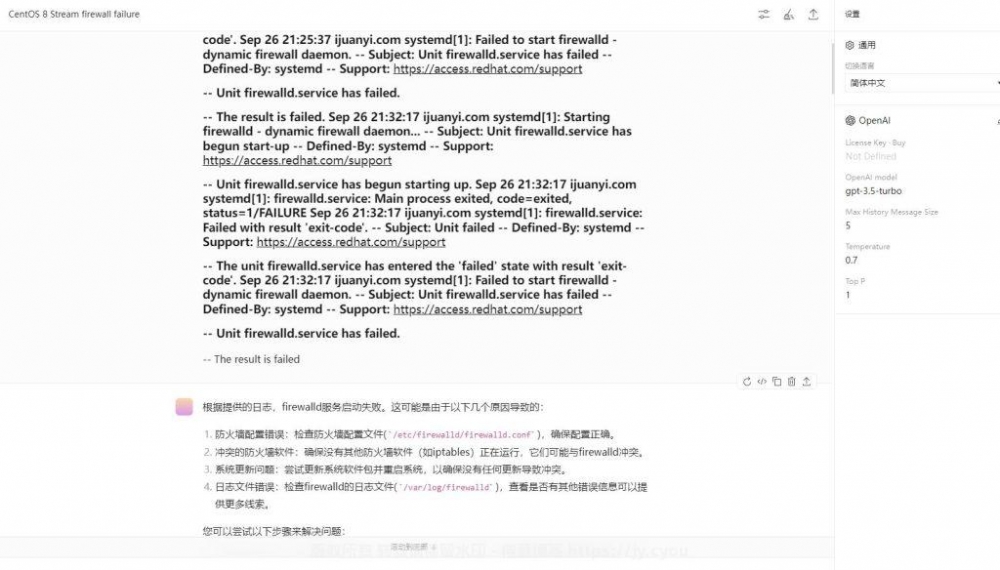
IP 禁封是指利用系统自带防火墙,拒绝蜘蛛 IP 连接,此措施最为严格,且针对有特定 IP 蜘蛛,如果 IP 是随机变动的, IP 禁封意义也不大。
以宝塔为例,在安全 &#󠄐󠄹󠅀󠄪󠄢󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮8211; 系统防火墙 –󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄐󠄹󠅀󠄪󠄢󠄡󠄦󠄞󠄧󠄣󠄞󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮󠄢󠄡󠄦󠄞󠄡󠄢󠄠󠄬󠅒󠅢󠄟󠄮󠄐󠅅󠄹󠄴󠄪󠄾󠅟󠅤󠄐󠄼󠅟󠅗󠅙󠅞󠄬󠅒󠅢󠄟󠄮󠅄󠅙󠅝󠅕󠄪󠄡󠄧󠄥󠄨󠄢󠄣󠄥󠄨󠄤󠄨󠄬󠅒󠅢󠄟󠄮 IP规则 – 添加IP规则 中添加你需要屏蔽的IP即可。

特别说明:
本文部分内容参考自以下网站:










暂无评论内容